Distributed systems fail in ways that monoliths never do. In a single process, if a function call fails you get an exception — simple, local, easy to reason about. Spread that same call across a network boundary and suddenly you’re dealing with partial failures, redelivered messages, timeouts that may or may not mean the operation succeeded, and cascading outages that start from something as mundane as a slow database query.
This post is about the patterns that make inter-service communication reliable — not just the happy path, but every failure mode that will eventually bite you in production.
When Does Reliability Actually Matter?
Not every system has the same requirements. Before adding complexity, be honest about what you actually need.
Reliability is critical when:
- Correctness affects money or legal standing — bank transfers, invoices, inventory adjustments
- Double-processing causes real harm — booking the same seat twice, charging a card twice
- You need a full audit trail — compliance systems, healthcare records, financial ledgers
It’s probably fine to be looser when:
- Data loss or duplication is low-stakes — analytics events, live metrics, view counts
- The reconciliation cost is trivial — a nightly job can heal inconsistencies cheaply
- You’re building something where “best effort” semantics match the domain — streaming, notifications, feeds
For everything in between, the patterns below give you a toolkit to dial up exactly as much reliability as you need.
Communication Protocols
Before diving into patterns, a quick orientation on the two families of protocols that matter most here.
Synchronous (HTTP/gRPC): Service A calls Service B and waits for a response. Simple to reason about, easy to trace, but tightly couples availability — if B is down, A’s request fails immediately.
Asynchronous (Message Queues): Service A publishes a message to a broker (SQS, RabbitMQ, Kafka) and moves on. Service B consumes it later, on its own schedule. Decouples availability, but introduces eventual consistency and more complex failure modes.
Most real systems use both. The patterns below apply to each, sometimes differently.
Idempotency: The Foundation
Idempotency is the property that says: performing the same operation multiple times has the same effect as performing it once.
In distributed systems, retries are inevitable. A network timeout doesn’t tell you whether the operation succeeded or failed — it just tells you the connection dropped. To retry safely, the operation must be idempotent.
Naturally idempotent operations:
- Setting a field to a specific value:
UPDATE user SET status = 'active' WHERE id = X - Inserting with an upsert:
INSERT ... ON CONFLICT DO NOTHING
Not naturally idempotent:
- Incrementing a counter:
UPDATE balance SET amount = amount + 100 - Appending to a list
For the non-idempotent cases, the standard approach is an idempotency key — a unique identifier attached to the operation that the receiver tracks in persistent storage:
-- Receiver checks before processing
SELECT 1 FROM processed_events WHERE event_id = $1
-- If not found, process and insert atomically
INSERT INTO processed_events (event_id, processed_at) VALUES ($1, NOW())
A unique database constraint on event_id gives you safety for free: if two workers race to process the same message, one insert succeeds and one gets a constraint violation, with no double-processing. This is the same mechanism used by Stripe, Braintree, and most payment processors when they expose an Idempotency-Key header.
Another approach is timestamp-based ordering: attach a created_at timestamp to each event and reject any event whose timestamp is older than the last processed timestamp for that entity.
Async: Message Queues
Message queues are the backbone of resilient async communication. The basic topology is Producer → Queue → Consumer, but the interesting part is what happens when things go wrong.

Happy Path
- Producer publishes a message to the queue
- Consumer picks it up, processes it, and ACKs (acknowledges) the message
- Queue removes the message
The ACK is the critical safety mechanism. Until the consumer sends an ACK, the queue considers the message “in flight” and won’t redeliver it — but it will redeliver if the consumer disappears.
When the Consumer Crashes
If the consumer process crashes mid-processing (hardware failure, OOM kill, deployment), the message never gets ACKed. Most queue implementations expose a visibility timeout — a window within which the message is hidden from other consumers while one is processing it. When that window expires without an ACK, the message becomes visible again and another consumer instance picks it up.
This means your consumer must be idempotent. The same message can and will be delivered more than once. Design for it, not around it.
When There’s an Application Error
If the consumer receives a message but throws an exception during processing (downstream service down, unexpected data, bug), the message is typically marked as failed. The pattern here is a Dead Letter Queue (DLQ): after N failed attempts, the message is moved to a separate queue where it sits until a human (or an automated recovery process) handles it.
The DLQ is not a graveyard — it’s a holding area. You need:
- Metrics on DLQ depth (alert when non-zero)
- Tooling to inspect DLQ messages (what failed, why)
- A process to replay DLQ messages once the underlying issue is fixed — which is why idempotency matters again
Sync: HTTP and the Circuit Breaker
HTTP communication is simpler to reason about but more fragile by default. When Service A calls Service B and gets an error, it has a few options.
Transient errors (network blip, momentary overload) are best handled with retries with backoff. The Fibonacci sequence works well for retry delays: 1s, 1s, 2s, 3s, 5s, 8s… It keeps early retries fast while avoiding thundering-herd problems under sustained load.
Sustained failures call for a circuit breaker.

The circuit breaker is a state machine with three states:
- Closed (normal): Requests pass through. The breaker counts failures. Below a threshold, all is well.
- Open (tripped): Too many failures in a window. New requests fail immediately without hitting the downstream service. This protects both the caller (no more waiting for timeouts) and the dependency (no more load while it’s struggling to recover).
- Half-Open (probing): After a timeout, a small number of requests are allowed through as a probe. If they succeed, the breaker resets to Closed. If they fail, it trips back to Open.
Well-maintained libraries handle this for you: Polly (.NET), Resilience4j (Java), cockatiel (Node.js), gobreaker (Go).
What to Do After Propagating the Error
Once you’ve retried and the circuit is open, you need to handle the failure at a higher level. What happens depends on how the original operation was triggered:
| Origin | On failure |
|---|---|
| HTTP request handler | Return HTTP error to caller (let them retry) |
| Queue message consumer | Let message fail → DLQ |
| Background/batch job | Leave record in “pending” state for next run |
The key principle: never silently swallow errors. Every unhandled failure should leave a trace — in a queue, in a database record state, in an alert.
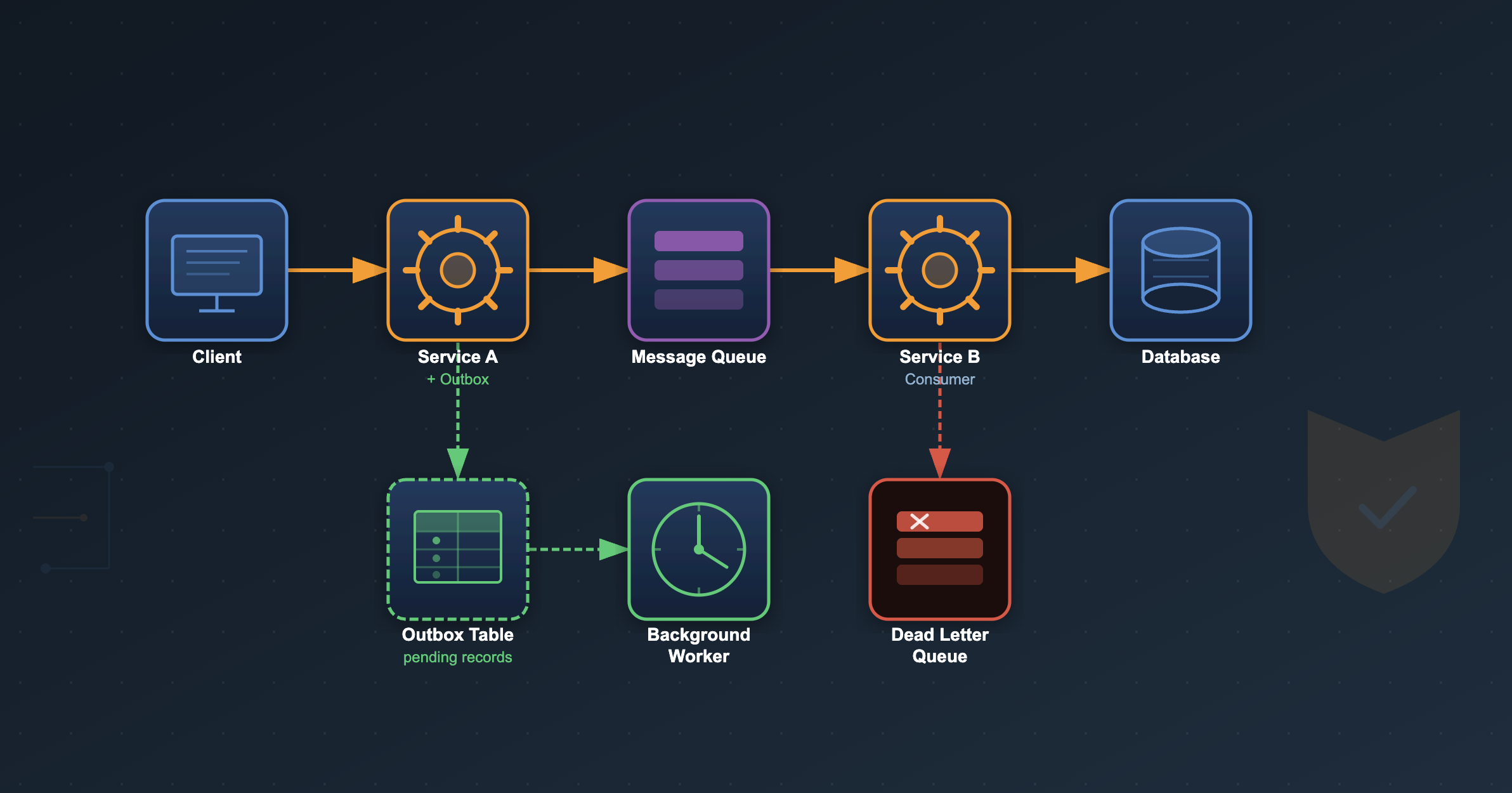
The Outbox Pattern: Atomic Multi-Target Updates
Here’s a scenario that breaks naive implementations: you update your database, then try to publish a message to a queue. Between those two operations, your process crashes. The database has the update; the queue never got the message. Your system is now inconsistent and there’s no record of the gap.
The Outbox pattern solves this with one rule: never publish messages or make side-effect calls outside of a database transaction.

Instead of calling the queue directly, you write a record to an outbox table inside the same transaction as your business data change:
BEGIN;
-- Business operation
UPDATE balance SET amount = amount + 100 WHERE user_id = $1;
-- Side effect deferred to outbox
INSERT INTO outbox (id, event_type, payload, status, created_at)
VALUES ($2, 'PAYMENT_RECEIVED', $3::jsonb, 'PENDING', NOW());
COMMIT;
Either both rows commit or neither does. Atomicity guaranteed.
A background relay worker polls the outbox table for pending records and dispatches them — publishing to a queue, making an HTTP call, whatever the operation requires — then marks each record as DONE. If dispatch fails, the record stays PENDING and is retried on the next poll.
-- Worker marks record done after successful dispatch
UPDATE outbox SET status = 'DONE', processed_at = NOW()
WHERE id = $1 AND status = 'PENDING';
Because the worker may retry the same record (worker crash, race condition), the downstream handler must be idempotent. There’s that word again.
Operational requirements:
- Alert on
outboxrecords that arePENDINGfor too long (broken worker, dispatcher bug) - Alert on records in
FAILEDstatus (permanent errors that need manual intervention) - Consider a
retry_countand max retries before moving toFAILED
A note on database support: ACID transactions with multi-table atomicity are available in PostgreSQL, MySQL, SQL Server, Oracle, MongoDB (multi-document transactions), and DynamoDB (TransactWrite API). The pattern works with any of them.
Putting It All Together: Payment Processing
Let’s walk through a concrete system that combines all of these patterns.
The problem: We have a payment webhook that receives a POST from the bank when a payment is received. We need to:
- Update the customer’s balance
- Notify the compliance team (via RabbitMQ for async processing)
- Notify the user (via HTTP to a notification service)
All three must eventually happen, consistently, with no double-processing.

The Flow
① Bank → API Gateway → Webhook Service
The bank sends a POST with a payment_id. The webhook service checks the payment_id against a processed_webhooks table — if already seen, return 200 OK immediately (idempotent receiver). Otherwise proceed.
② → ③ Webhook Service publishes to SQS
Rather than processing inline (which risks timeouts, and the bank retries on non-2xx), the webhook service publishes a message to an SQS queue and returns 200 OK immediately. The bank is happy.
④ SQS triggers the Balance Service
SQS delivers the message to the Balance Service consumer. The consumer begins processing. If the consumer crashes, the message reappears after the visibility timeout. Idempotency check at the top of the handler guards against double-processing.
⑤ Atomic DB transaction
Inside a single transaction, the Balance Service:
- Updates the customer’s balance
- Inserts an outbox record for compliance notification
- Inserts an outbox record for user notification
- Commits
If any of these three fail, the whole transaction rolls back. The SQS message will be redelivered and the handler will re-attempt from scratch.
⑥ ⑦ Outbox workers dispatch in the background
Two background workers (or one worker handling both types) poll the outbox table:
- Compliance worker: publishes a
CHECK_PAYMENTmessage to RabbitMQ, marks outbox recordDONE - Notification worker: calls the notification service HTTP endpoint, marks outbox record
DONE
Both workers use idempotency keys when dispatching so that retries don’t cause double notifications.
If a dispatch fails repeatedly, the outbox record moves to FAILED and an alert fires.
What the Monitoring Stack Watches
| Signal | Threshold | Action |
|---|---|---|
| SQS DLQ depth | > 0 | Page on-call |
Outbox PENDING age | > 5 minutes | Page on-call |
Outbox FAILED count | > 0 | Page on-call |
| Circuit breaker open events | Any | Log + alert |
| Compliance/notification HTTP error rate | > 1% | Alert |
Summary
Reliable distributed communication comes down to a small set of composable principles:
- Make handlers idempotent. Retries will happen. Design for them.
- Use dead letter queues for async failures, and alert on them.
- Retry with backoff for transient HTTP errors; use a circuit breaker to stop hammering dependencies that are clearly down.
- Use the outbox pattern when you need atomic “at least once” delivery across multiple targets — never write to a queue and a database in separate operations.
- Monitor aggressively — DLQ depth, outbox staleness, circuit breaker state. Silent failures become production incidents that wake you up at 3am.
The patterns aren’t complex individually. The discipline is applying them consistently, across every service boundary, before the incident that would have motivated you to do so.